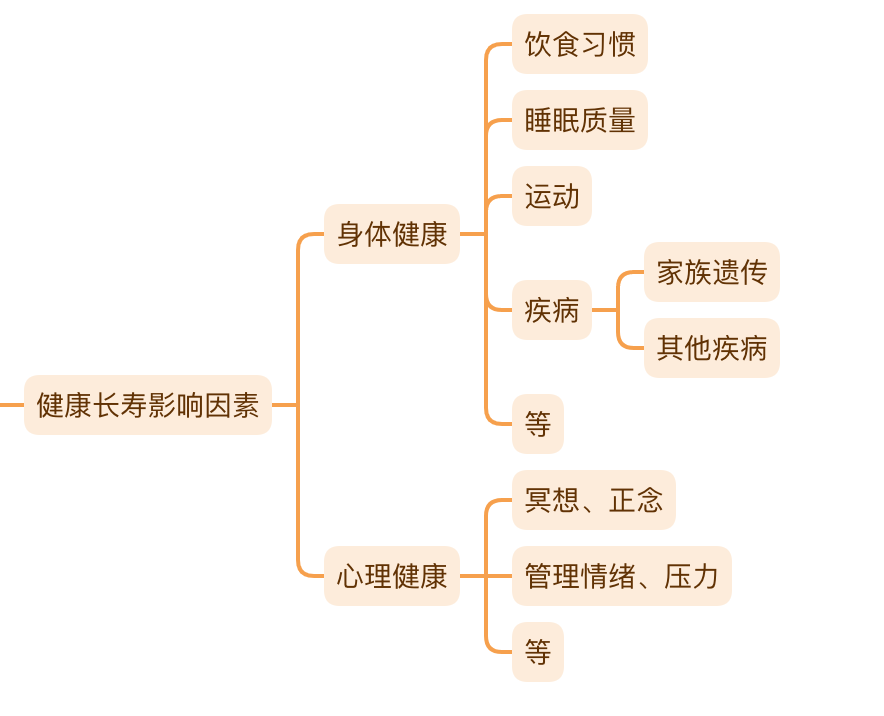
前言五一期间阅读完毕了《小强升职记》一书,感觉收获颇丰,对自己的时间管理进行了更加深入的思考和了解。本文就针对我在阅读过程中所记录的一些笔记以及思考实践进行一个回顾总结。
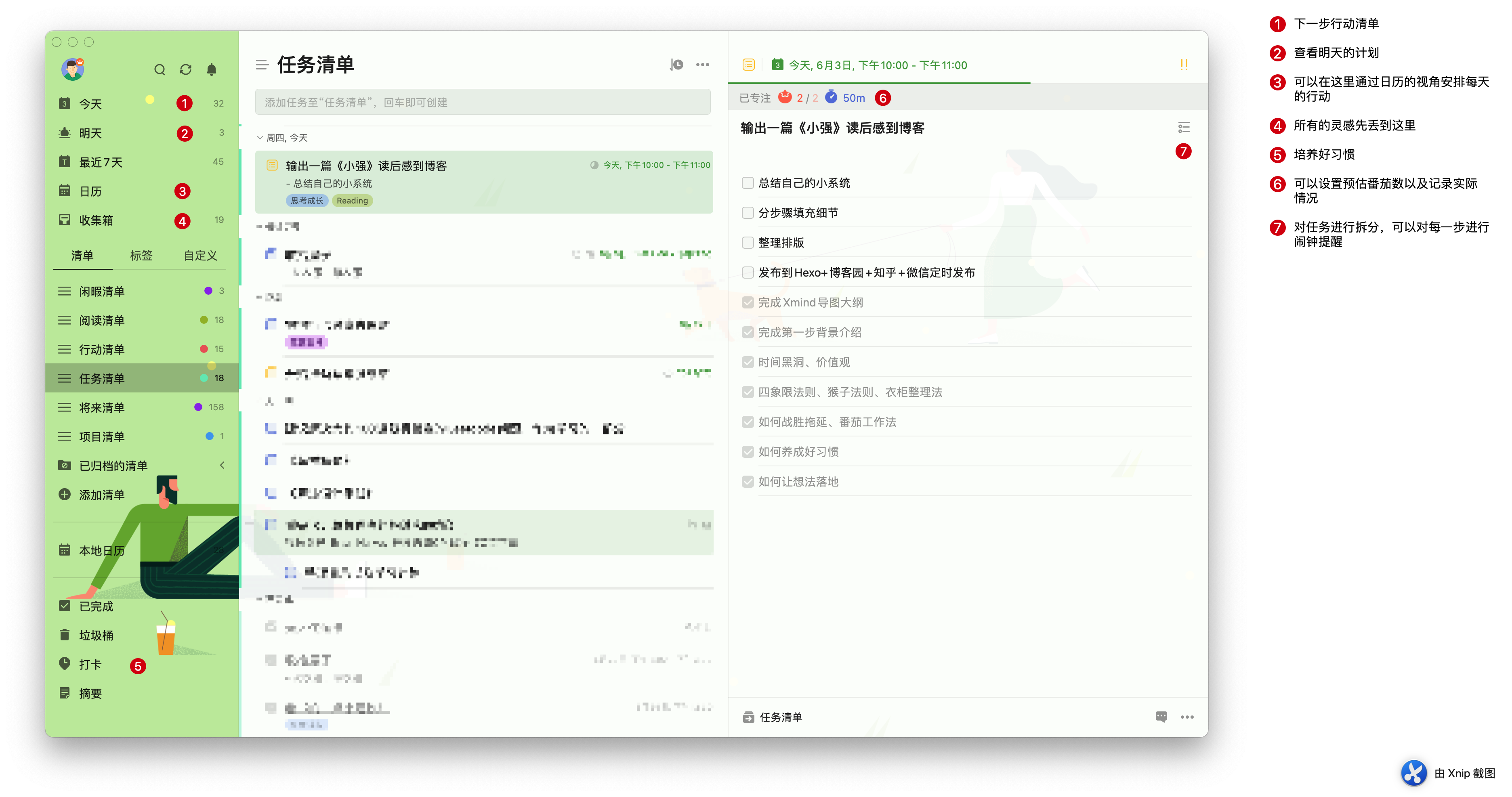
这本书的主线是介绍主人公职场菜鸟小强在大牛老付的帮助下,一步步理清楚自己在时间管理方面所犯下的一些错误,并且进行改正完善,之后慢慢从菜鸟走向一名比较成熟合格的技术负责人的整个历程,按照这条成长路线来进行叙述的。可以看出作者在这方面的功底非常深厚,深入浅出的就把时间管理中常犯的一些错误和如何应对逐步的展开来讲述。
作者类比了一棵树苗成长的过程来进行章节划分:
- 种子—找到时间黑洞,找出职业价值观
- 树苗—学习四象限法则、衣柜整理法
- 枝叶—如何战胜拖延,如何要事优先,如何处理临时突发事件
- 开花—如何养成一个好习惯
- 结果—如何让想法落地
- 收获—如何建立高效办公区,逐步走向高效率、慢生活
我感觉这个类比稍稍有点不是很切合,全文比较干货的是在第二章,详细介绍了一些非常实用的时间管理工具,其中有不少是我之前就一直在实践的,但系统的跟着作者再次学习一遍,感觉自己之前只是了解了一些皮毛。这也给了我一个教训,自己随便网上搜了一下一些概念,然后就上手实践是有一些不太可取的地方的,还是需要通过书籍来深入了解一下背后的思想理念,相比于附带的知识价值来说,书籍真的是非常非常便宜的东西了。
接下来我简单按照阅读的顺序进行一些重点汇总。
消灭时间黑洞
开篇老付先是通过给小强介绍“时间黑洞”的概念来引导小强进行思考和记录,明白时间黑洞在我们日常工作生活中的占比有多高。尤其是当下我们这个信息洪流时代,可以说你的专注力无时无刻不在被周围各种信息所打断所消耗。打个比方说,你只是想要打开手机搜一下某个资料或者文章,解锁手机之后发现有人给你发微信消息,赶紧点进去看看内容,聊了一会之后,收到了新的公众号提醒,翻进去看了一下,又弹出微博或者抖音的推送消息,当你刷了半小时抖音之后,已经完全不记得之前想要查找什么了。可以说这已经成为一个很普遍的现象了,毕竟现在专门有着高薪的产品经理在研究如何做出一个紧紧抓牢你的产品,配合人工智能大数据等,例如抖音会给你疯狂推送你喜欢看的内容,几乎可以做到让你一下午坐在沙发里面刷抖音刷到水都想不起来喝一点。这也是我为什么越来越不喜欢在手机上进行深度阅读和思考的原因,不要太高估你的意志力和专注力,也不要低估你手机上那些 APP 对你的影响。
老付给出的解决方案是进行时间日志记录,这里有两种记录方式。首先,刚开始使用的时候,可以把自己每天的时间花费在哪些事情上面挨个记录下来,知道自己一天有多少时间是真正工作的时间,有多少是划水、玩手机等;之后,慢慢了解了自己的时间使用分布,可以先设定一下自己今天的时间安排,最好细化到每个小时,然后记录实际完成情况,中断次数等,目的是为了明确自己被打断的频率,自己的高效工作时间。
这里可以推荐几个我在实践过程中发现的比较切合这个场景的软件。
首先,Mac 上可以使用”Qbserve”软件,它可以很方便的记录你在使用电脑时候的效率情况,包括每个 APP 的使用时长、浏览的每个网站等,还是蛮细致的,但它有个很明显的缺点,无法记录手机时间,同时跨设备目前还不支持。手机上可以使用“时间块”这款软件搭配使用,用来标注自己每天的时间使用情况,不过它也有个明显的缺点,自动化程度太低,几乎全是要靠手动点击操作,尽管软件已经简化了使用步骤,但每天到了晚上提醒的时候,回想一天的事情,然后一个个点击,其实还是蛮消耗精力的。
Qbserve 截图:
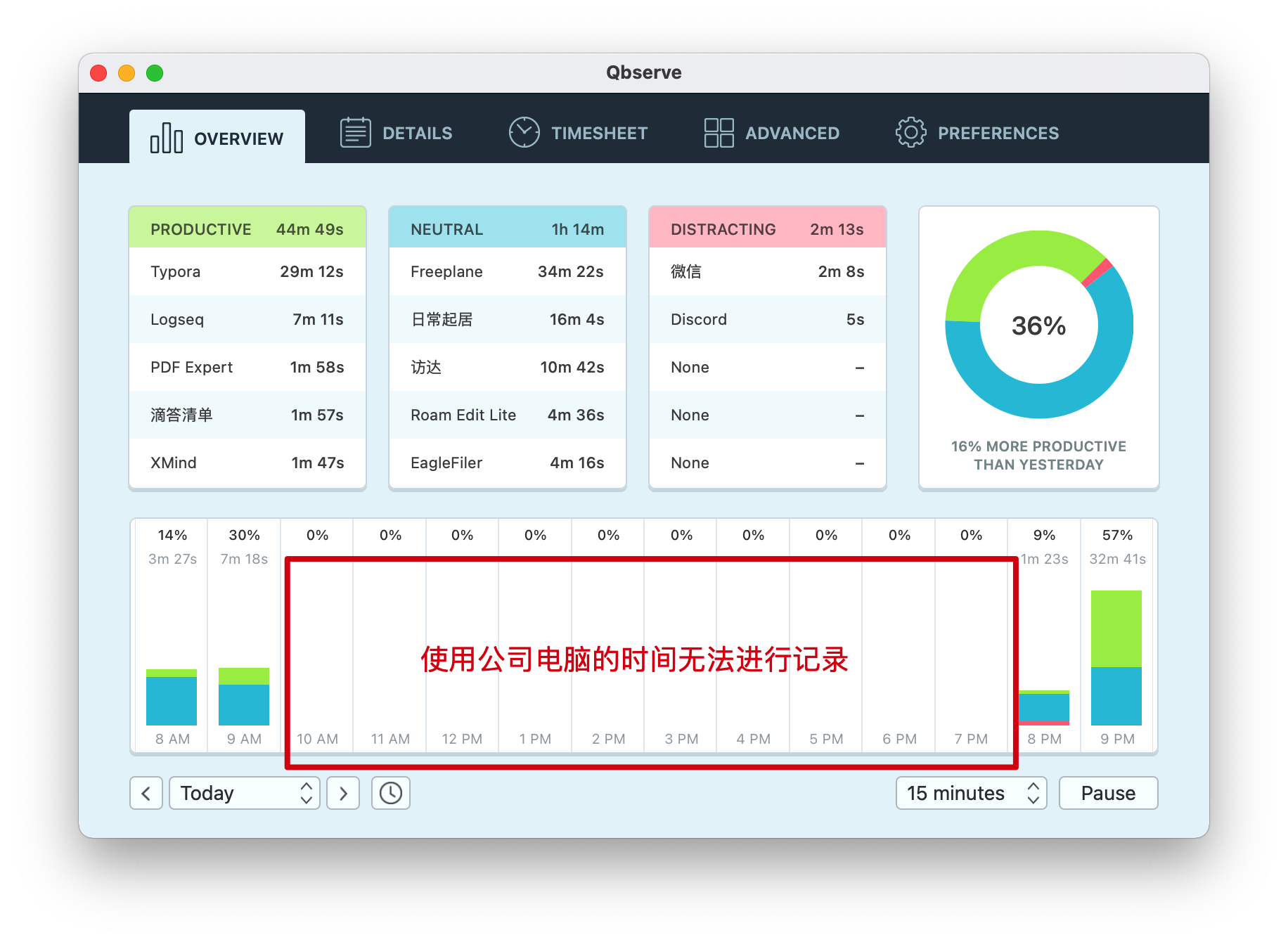
时间块截图,可以看到每天实际认真工作的时间比你想象的要少得多:

其次,需要安排自己每天的工作,细化到下一个小时应该做什么,然后记录下实际完成的情况,包括被打断的情况,坚持一周之后你就可以知道自己的高效时间段在哪里。通常来说,一般人的精力是跟血糖浓度成正比的,所以为什么快到饭点的时候效率很低,就是因为血糖含量较低,所以上午 10-11 点,下午 2-4 点通常效率是比较高的。但是由于白天被打断的频率会比较高,也会有很多人喜欢在晚上甚至夜里工作,这样更容易专注,找到适合你自己的高效时间段是很有必要的,因人而异。比如我自己,最近发现早上效率还蛮高的,没有人打扰,所以我最近在坚持早起,每天 7 点半左右起床,离 9 点出门上班,中间有一个多的专注时间,可以用来进行看书、写作等,同时中午公司一般有午休习惯,我会提前去吃中饭,在吃过中饭之后快速进行一会午休,然后在大家还在休息的时候,可以找到大约半小时左右的专注时间,用来思考下午的工作,或者完成一些比较重要的工作。
找到高效时间的意义是什么呢?这里有一个原则叫做“三只青蛙”,就是说每天早上梳理出当天必须要完成的三件事情,通常是重要性或者困难度比较高的事情,优先把这几件事情完成,其余的零碎小事做不完也没有关系。所以找到你最高效的时间段,安排“三只青蛙”就显得比较重要了。
书中讲到一个例子十分发人深思:同事 A 每次重要的事情都能办的很棒,但是在一些零碎小事上经常出问题;同事 B 平时各种小事做的很好,但一旦遇到重要的大事,就出幺蛾子。如果你是老板,会如何对待这两位同事呢?答案很残酷,从老板的角度考虑,重要的事情办的很棒的同事 A 明显是可以委以重任的,可能还会给他安排一个秘书或者助手协助完成一些琐碎的小事;同事 B 一到关键时刻老是掉链子,那么就把各种琐碎小事都分配给他。这样的结果就是同事 A 逐步得到重用,且每天只需要完成一些重要的事情即可;同事 B 逐步被边缘化,永远只能在琐碎的小事中忙的不可开交。所以找到对老板来说比较重要的事情来做,以及锻炼自己完成要事的能力是非常重要的。
明确自己的职业价值观
那么如何判断一件事情对你来说有多重要呢?随后作者给出了一个评判标准: 职业价值观。
所谓价值观是指一个人对周围的客观事物(包括人、事、物)的意义、重要性的总评价和总看法。
职业价值观指的就是对于你的职业生涯来说,你对平时遇到的这些客观事物的意义、重要性的评价和看法。听起来是很虚的东西,这里作者提供了一个如何找到职业价值观的方法,是一套职业价值观自测的题目,我在网上找到了对应的网站: http://www.181du.com/survey/Workvalues/index.aspx 。
一共 52 道题目,我自己做下来之后,得到的排名前三的价值观分别是:智力刺激、人际关系、社会地位。
不过思考下来,你就会发现这里作者讲的还是稍微有点不够透彻,价值观跟日常事情的评判中间感觉缺失了一个环节。首先,这个价值观题目你做完之后,会发现并没有特别深的感触,起码对我来说是这样,并不会有那种开悟的感觉,一下子就知道了自己的目标之类的,甚至你可能都觉得它不准;其次,有了这个价值观之后,你就知道如何评判一件事情的重要性和优先级了嘛?好像也并没有,实操性有点差。
我个人觉得,价值观可能只能作为一个指导思想,引导你进一步进行思考,实际上如果真的想要做到日常事情可评判,还需要一个更近期的目标和工具,为了解决这个问题,通常公司里面都会进行目标管理,一般使用 OKR 或者 KPI 这样的工具进行管理。对于个人来说,也可以设定一个未来 3-5 年的目标,然后逐步拆解,做一个年度计划,月度计划等,这样你就知道现在分配给你的事情对你来说优先级如何,接下来应该做什么。这个目标制定感觉后面讲到的六个高度更加贴近实际使用。
时间管理工具
这一章我自己感觉是这本书最精华的部分,起码对于初步开始进行时间管理的我来说是这样,介绍了很多实用的管理工具和思想。我印象最深的就是:
做事要考系统而不是靠感觉
之前虽然也有积累一些自己的小系统,但是并没有这么明确的提出来,看到这句话的时候确实有点共鸣,有点类似于之前看过的《清单革命》一书,后面会注意把自己平时逐步在形成的小系统全部记录下来,真正的做到处理各种事情都有固定套路,这样才能既高效又不容易出错。
四象限法则
这篇里面很核心的一个内容就是介绍四象限法则,这个大家应该都已经听过了,所有的待办事项按照重要性和紧急程度可以划分为重要且紧急、重要不紧急、紧急不重要、不重要不紧急四类。
首先,我们要明确的是,待办事项的重要性和紧急性是如何判断的呢?原则如下:
- 重要性可以根据你自身的职业价值观或者职业规划来进行
- 紧迫程度取决于任务的截止时间,这个很好理解,毕竟 Deadline 是第一生产力~
其次,我们要知道如何应对这四个象限的任务:

如上图所示,这里的原则是:
- 重要且紧急的事情,需要立马去执行
- 重要且不紧急的事情,需要制定工作计划,定期去执行
- 紧急但不重要的事情,可以委托他人完成
- 不重要不紧急的事情,拒绝完成
下面我们详细展开一下:
重要且紧急-立刻去做
这个没什么可说的,应该是去立马完成的。
我们工作中的主要压力就来自于第一象限,我们生活中的主要危机也来自于第一象限。
不过这里有个点需要思考的是,我们需要避免太多事情进入第一象限,原因也很简单,他会毫无原则的排挤开其他任何事情,独占你的时间,那么随着进入这个象限的次数越来越多,你会逐渐被事情推着走,变得毫无目的的不停地忙碌,这当然不是我们想要的。
那么应该如何减少进入这个象限的次数呢?应该说进入这个象限的任务大多数是由于第二象限没有处理好导致的。例如,下个月要进行一次汇报,正常情况下应该提前完成部分工作,例如整体大纲,部分材料收集等等,但由于人天然的惰性,不到 DDL 绝不动工,那么当你发现明天或者后天就要进行汇报的时候,这个事情就进入到了第一象限,导致你不得不连续熬夜完成它,同时效果必然会打折扣。
重要不紧急-优先把精力投入到这个象限
有计划的去完成。通常来说,这个象限的事情都是一些需要长期坚持,且短时间内很难看到明确收益,换句话说也就是延迟满足的事情,例如,阅读一本书、学习一门语言等等。
第二象限的优先级是最高的,因为它的长期收益最大,对你的成长最有帮助。但大多数情况下都被第一象限或者第三象限那些更紧急的事情阻塞导致没有进展,人总是会优先处理那些简单且有明确时间的事情,这样的好处就是可以得到及时反馈和满足,这个是人类的天性,正常是很难跳出这个坑的。
那么我们应该如何让自己尽可能的多处于第二象限呢?
消除时间管理的三大杀手——信息不够、拖延、预期结果不明确。
我们需要对收集篮里面的任务或者待办事情进行进一步的处理,针对上面提到的时间管理的几个坑:
- 尽可能明确更多信息。包括执行步骤、上下文、起止时间
- 步骤拆分的尽可能细。人总是喜欢及时反馈,所以我们要把步骤分解的更细,这样每天都可以完成一小部分
- 写清楚最终目标。这点也是我经常忽略的,对于一个长期任务来说,明确任务预期效果是很重要的,这样我们就可以知道完成的情况、是否需要调整以及以后应该如何优化
- 计划花费的时间。提前对该工作进行评估,可以使用甘特图等工具辅助
- 负责人是谁。明确第一责任人,事情才能推进的更顺利
紧急不重要-委托别人去做
委派给他人去完成。通常来说,这个象限经常会出现一些零碎的小事情,可能完成它对你来说并不会有太大成长,但是由于是老板指派或者是某个大项目中的一个不可或缺的环节又或者是他人的一些请求,导致你不得不停掉手上其他事情来完成它。这里有一个很有意思的“猴子法则”可以帮助你跳出这个象限。

比尔·翁肯(Bill Oncken)曾经提出一个理论,叫‘背上的猴子’。翁肯教授有一次偶然发现,自己在忙于加班的时候,下属竟然在优哉游哉地打高尔夫。这让他突然领悟到,主管人员之所以时间不够用,一个很重要的原因在于没有做好授权分责,将太多本该下属去做的工作招揽到了自己身上,以至于永远在苦苦追赶工作进度。
这里的猴子,指的就是待办的事情和职责。例如,中午休息的时候突然遇到了愁眉不展的同事,经过询问,原来是被某个技术难题所阻塞了,经过半小时的讨论发现确实是个棘手的问题,你一时半会也没有思路,这时候你说我回去再想想。之后这个猴子就从同事身上跑到了你的身上,然后同事就可能琢磨别的问题了,过半天过来问一下,上次那个问题有方案了吗?这时候你就会发现你的时间慢慢被这些原本不属于你的事情和职责所沾满了,导致你无法完成自己的第二象限甚至第一象限任务。
当然,帮助他人是有必要的,前提是你要先完成自己的事情,且要注意分寸,明确职责,避免让他人的事情成为你的事情,不要轻易的被他人“赋能”了。
下属问:我们怎么解决项目预算超支的问题?
你回答:你有什么想法?能不能先请你做一个删减成本的计划案?
不过这里有两个重点一定要明确:
- 明确职责,确定这只猴子不是你的。否则就变成了你在推卸责任。
- 注意沟通方式,明确、坚决、不生硬。
那么如果有些时候,确实有一些老板指派的或者他人的事情不得不你来完成,应该如何处理呢?这里需要加上你自己的思考,了解清楚这个任务的上下文背景、明确具体的时间点、同时需要问清楚预期结果,也就是上面提到的“信息不够、拖延、预期结果不明确”。
不重要不紧急-避免做
这个没什么可说的, 尽量不做,尤其是尽量别在工作时间进入该象限。比如玩游戏、看电视剧、刷抖音什么的,偶尔忙碌空闲可以稍微放松一下,但是注意分寸,毕竟现在的手机软件太吸引注意力了,很容易就陷入“时间黑洞”中而不自知。
衣柜整理法(GTD 工作法)
这篇主要是介绍了一下如何实践 GTD 工作法,作者形象的比作衣柜整理法,之前我对 GTD 也多少有些了解,但并没有知道的这么详细,下面详细记录一下。
GETTING THINGS DONE® is a personal productivity methodology that redefines how you approach your life and work.
GTD 是由 戴维·艾伦 在《搞定》一书中提出的方法论,这里是官方网站。它的目的是用来快速整理你的日常生活和工作,把他们从混乱变得井井有条。
GTD 包含 5 个步骤:
CAPTURE 捕捉
捕捉的意思是说,有任何想法、接到新的任务,不要中断当下的事情,而是应该把这些想法和任务记录下来,存放到收集篮(Inbox)中。
这里需要遵循的原则如下:
- 捕捉工具越少越好。避免成为工具控,工具切换的越多,越不容易快速记录,也不容易汇总之后进行组织整理。可以使用笔和纸,也可以使用软件,可以使用绘画板,但是不要同时使用这些工具。
- 保证 5 秒钟进入录入状态。确保你的录入流程尽可能的短,这样是为了避免对当前工作产生太大影响。试想一下,如果你记录一下灵感就花了 1 分钟,那么等你回到当前工作时候,还需要重新梳理上下文,进入状态,效率肯定是很低的。
- 定期清空收集篮。避免让你的收集篮成为一个永远不打开的仓库(说你呢,Evernote),只收集不执行就没有任何意义。这点也是我当前做的最不好的地方,一起共勉。
CLARIFY 明确意义
目的是为了分辨出待办事情中哪些是可以立刻行动的,哪些是需要进一步处理的。
这里并不是要实际执行行动,而只是单纯的确认这些事情要怎么处理,也就是判断重要性、识别急迫程度、明确优先级、是否可以指派给他人、是否可以在两分钟内完成等。
原则:
- 从最上面一项开始处理
- 一次只处理一件事
- 永远不要再放回收集篮(被迫中断的事情除外)
三类不能行动的任务
- 垃圾: 这个应该直接过滤掉,不应该进入收集篮浪费时间
- 将来某时:
- 例如整理办公室、收拾屋子等等,并不是特别紧急,
- 处理方式:记下来,有空去做
- 参考资料:
- 处理方式: 分类归档,这里可以参考 PARA方法进行管理,内容较多,后续单独介绍一下。
六类可以行动的任务
- 2分钟行动:
- 参考 “两分钟法则”,也就是说某件事情如果两分钟内可以完成,那么就立刻去做
- 项目: 需要多个步骤,并且多部门协调的事情。
- 任务: 需要多个步骤,但可以自己独立完成,拆解为多个行动
- 行动: 可以直接去做的事情
- 指派给他人:
- 告诉别人这件事的意义、同时明确想要的结果、以及截止时间
- 然后在日程表里面加一个定时提醒,用于问询结果
- 特定时间做的事: 放到日程表里面
行动、任务、项目的区别
- 行动可以直接去做,决定的下一步是具体的时间点
- 任务和项目都是由多个行动组成的,但是任务基本由自己独立完成,关注的重点是事情本身;项目关注的重点是人与人的沟通协调。
- 决定项目的下一步行动是建立框架,也就是涉及到的资源、干系人等
- 行动关注事情的执行,搞定任务的终点是先想清楚结果图像是什么,然后找出实现这个结果的路径,做项目既要知道怎么搞定人,还要把握好这些人的执行情况。
ORGANIZE 组织整理
这里主要是按照上面已经明确意义的原则对待办事项进行整理,产出的内容:
- 日程表: 这个可以直接同步到系统日历,然后钉钉订阅一下,这样工作日程跟家庭日程都在一起了,便于查看和提醒
- 行动清单:每天的工作从这里开始,目前我是使用滴答清单来完成
- 项目清单:使用 “甘特图” 进行管理,也可以使用滴答清单
- 将来清单: 一般是不紧急,重要性也不是很高的事情,例如体检、洗牙等等。
REFLECT 深思
定期的对自己当前的任务进行思考,时间点推荐在每天下班和每个周末完成。包括:
- 孵化杂事
- 产生灵感
- 提升高度
- 回顾近期的任务完成情况,并且进行归纳总结,制定下一个周期的任务安排
- 每日回顾:可以参考每日日记
- 今天做了什么?
- 对哪些比较满意,哪些不满意?
- 推进了哪些重要的事情?
- 明天的规划是什么?
- 每周回顾:
- 清空收集篮
- 回顾一下将来清单、行动清单、项目清单
- 将来清单: 是否有可以孵化到行动清单的内容?
- 行动清单: 是否有过期任务需要调整?是否需要指定或者变更具体的日期?
- 项目清单: 自己下一步应该做什么?现在项目的完成度是多少?项目要取得什么样的成果?
- 检视日程表
ENGAGE 行动
确保脑袋里面只装一件事情,这里可以利用 番茄工作法,使用一些例如降噪耳机、白噪声等工具辅助自己提升专注力。
同时,通过把任务拆分的尽可能细,就可以在每完成一小步的时候就进行打勾消除,这是一种很有成就感的事情,这种正向反馈会激励你进一步完成后面的步骤,不知不觉中就把一个大任务完成掉了。
灵感收集技巧
这里有一些技巧可以用于提高行动的效率,主要是在快速记录待办清单的时候,对任务描述的足够清晰,因为在记录事情的时候你是很清楚要做什么的,但等真正开始做可能已经是几天后了,这时候还要拼命回忆之前的对话和上下文,比较费力。所以这里的技巧主要是用于消除不确定性:
- 秘诀一:动词开头。例如评估一下 xx 工作工期、去超市买 xx 等。
- 秘诀二:内容清晰。标注清楚具体的时间、地点等信息,可以参考 “5W2H原则”。
- 秘诀三:描述预期结果。在做这件事之前最好就先想清楚期望的结果,这样效率会更高,避免返工。
- 秘诀四:设定开始时间、周期、最后期限是什么,DDL的重要性大家应该都清楚了,没有截止日期的任务几乎等同于不会去完成。
专注技巧
- 关掉 QQ、微信、钉钉等即时通讯软件。也可以使用系统自带的勿扰模式,IM 软件对专注的打断是很要命的。
- 给水杯里倒满水,提前去上个厕所。确保接下来的时间不会因为身体需求被中断。
- 尽可能的隔离自己。例如使用降噪耳机、白噪声软件、专门找个安静的角落等等,避免走神。
- 无法集中精神时先休息一会。这个也是很重要的,毕竟人不是机器,总会有高效和低效的时候,不要强迫自己,给自己太大压力。
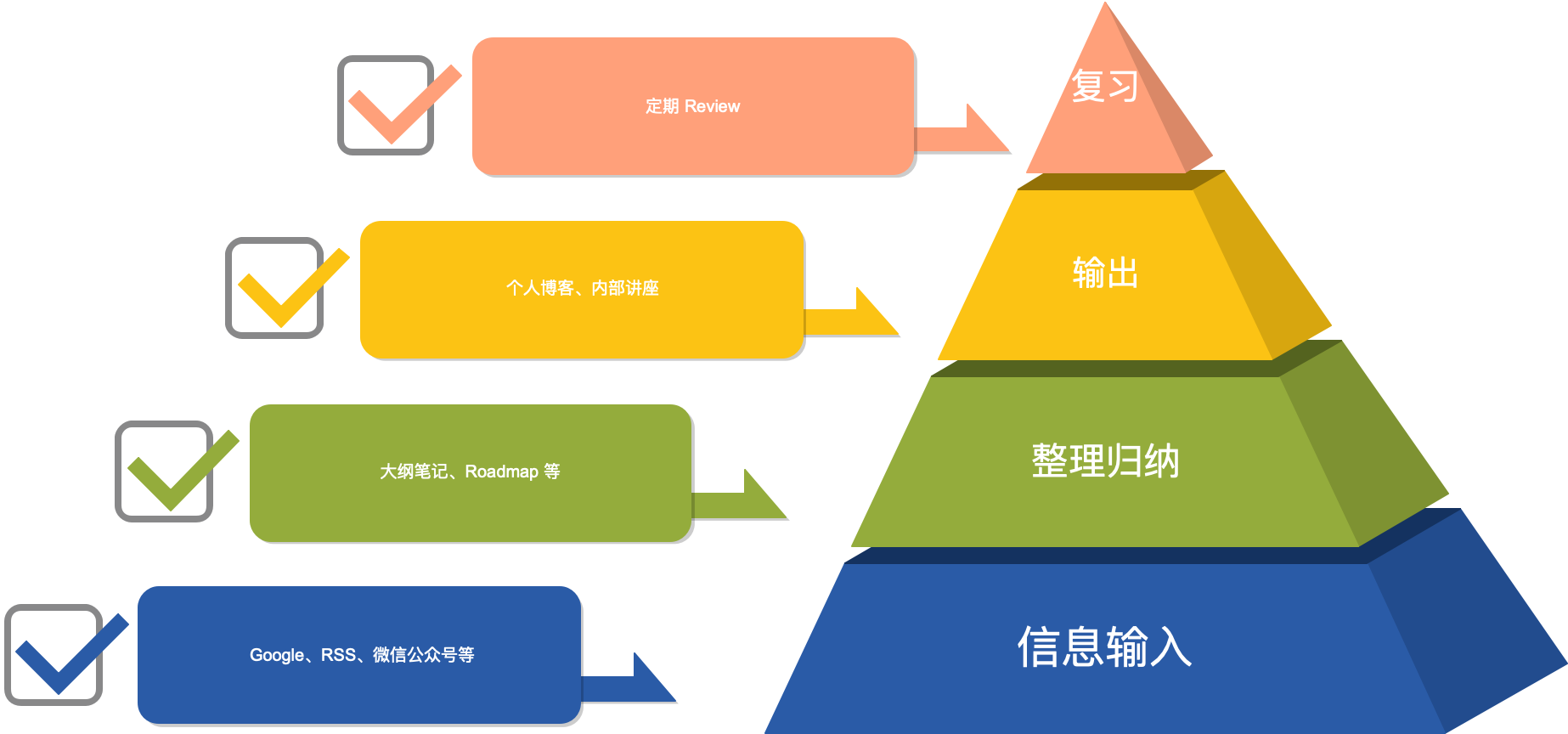
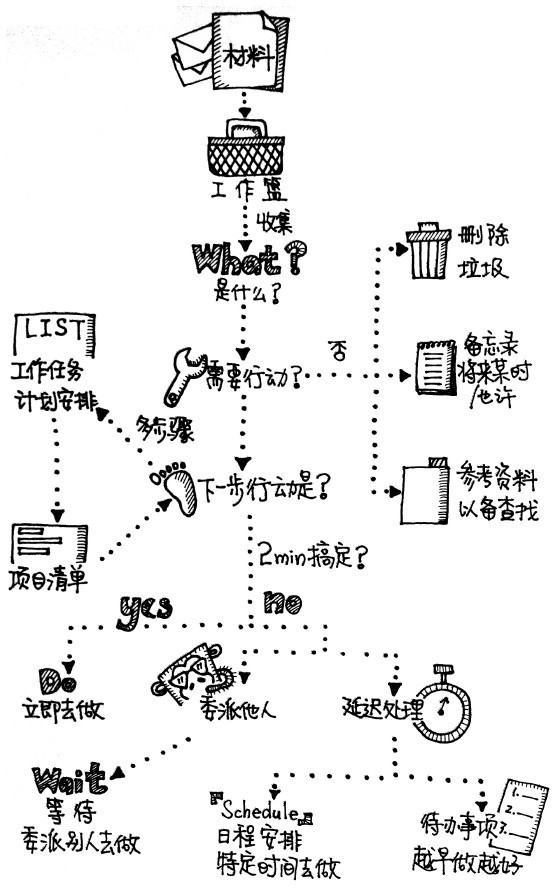
作者对上面的步骤汇总整理了一幅流程图,感觉很好的表达了 GTD 的主要步骤,可以时不时的拿出来翻阅一下:
精力管理
这部分主要是讲了两块内容,如何解决拖延症和如何使用番茄工作法。
关于如何解决拖延症这里基本思路类似于养成一个好习惯,在后面详细展开一下,这里略过。
番茄工作法

番茄工作法(英语:Pomodoro Technique)是一种**时间管理法**,在1980年代由Francesco Cirillo创立。
番茄工作法是一个易上手难精通的方法,说起来其实很简单,
- 设置一个待办任务
- 设置专注时间,通常是 25 分钟
- 持续专注工作,直到番茄结束
- 休息 5 分钟
- 进入下一个番茄
- 每 4 个番茄,进行一次长时间休息,15~30 分钟
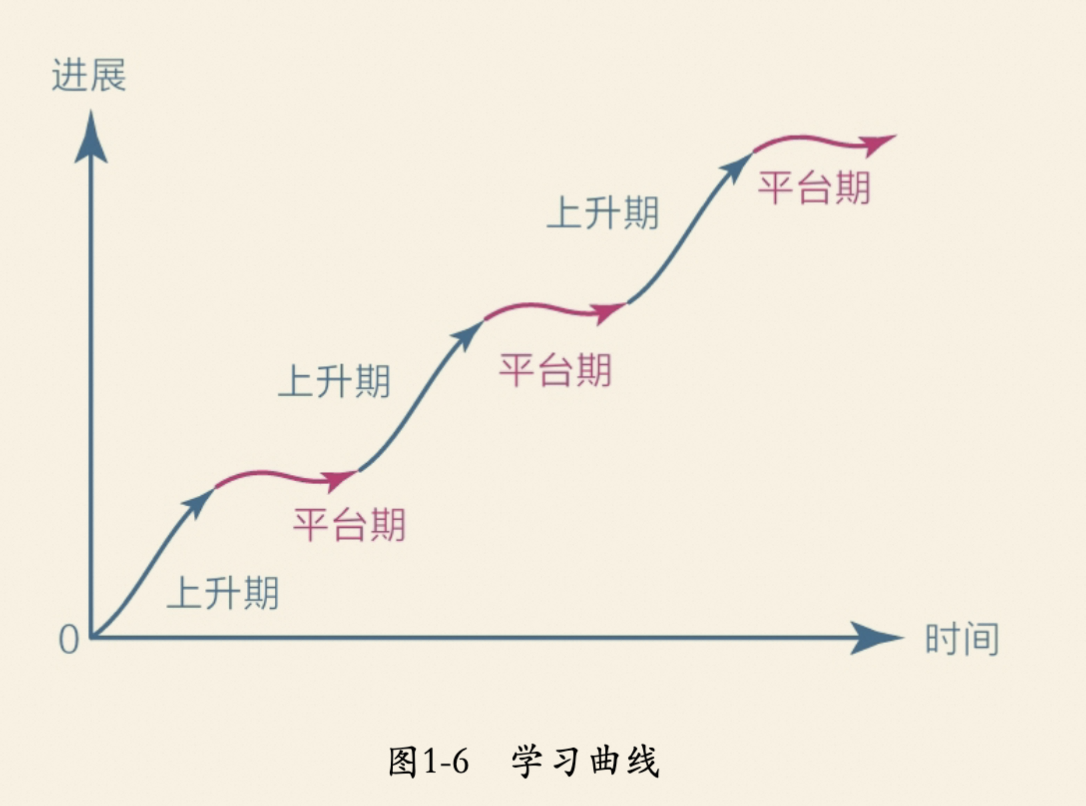
番茄工作法的原理是人的精力是会随着持续工作不断下降的,所以我们需要通过不断的短暂休息恢复部分精力,确保接下来能够高效工作,示意图如下:
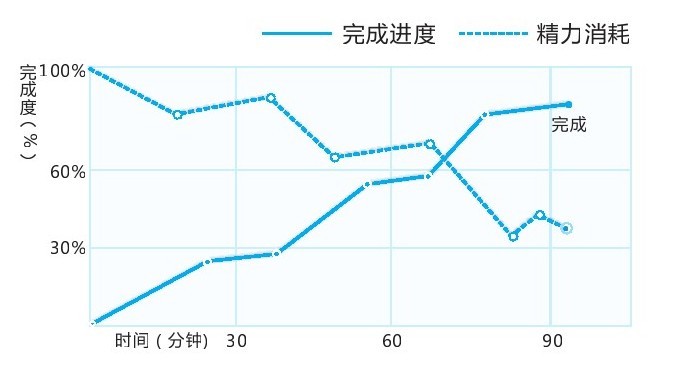
通常来说,这里最难得就是中间的 25 分钟专注工作,一般作为一个社畜,时刻要注意关注钉钉消息、被人当面找到咨询问题等等,很容易就会中断自己的番茄。如何才能最大限度的专注工作呢?
其实上面行动技巧里面已经基本都提到了,除了通过一些仪式或者建造更好更安静的工作环境以外,就是需要对 GTD 的不断实践,每次遇到中断事件的时候,仔细问一下自己,是否可以忙完手上现在的工作再去评估;最好就是直接先放入收集篮即可。
更具体的内容可以参考一下《番茄工作法图解》这本书。
习惯养成
这部分内容主要是介绍如何养成一个好习惯。我们都知道习惯的力量是很强大的,可以这么说,我们日常生活中有很大一部分行为是完全由习惯控制的。例如你每天早上起来第一件事就是先掏出手机看一下时间,然后刷一会朋友圈,不完全清醒的情况下已经完成了刷牙和洗脸;即使已经换了工位,刚开始几天还是会经常走错,等等。
同时我们经常会在新的一年给自己立一些“flag”,例如最多的就是,每天坚持跑步、每天坚持读书、坚持早睡早起、学习英语等等。但结果我们也都知道了,大多数人办完健身卡就等同于已经健身完了,之后再也没见过教练。
这里作者给出的解决方案是这么几个原则:
- 找到驱动力。首先你要明确自己为什么要培养这个习惯,只有足够强的自驱能力才能坚持的更久。
- 及时奖励自己。人都是喜欢做及时反馈的事情,每完成一个阶段就给自己一个奖励,会让你下阶段更加轻松。
- 找到志同道合的人一起培养习惯。找到趣味相投的人,大家相互督促,会比自己一个人坚持更加有效,毕竟人都是有惰性的。
我再补充一下我自己在实际实践过程当中的一些经验:
- “破窗理论”: 连续坚持 60 天通常比坚持 30 天后中断 3 天再坚持 30 天要简单很多,原因就在于“破窗理论”。以一幢有少许破窗的建筑为例,如果那些窗没修理好,可能将会有破坏者破坏更多的窗户。类比到养成习惯上来,一旦你连续坚持的好习惯,中间有某几天因为一些因素中断了,那么接下来你能继续坚持的概率远小于未中断的时候。可以简单地理解为人们都有保持完美的心理,一旦发现这件事情不是那么完美了,就很容易破罐子破摔,觉得即使后面坚持了也没太大意义了。从这里我得到的启发是尽可能保持你的习惯连续性,真的有不可抗力因素导致中断,也要立马补上。
- “崔西定律”: 任何工作的困难程度与其执行步骤数目的平方成正比。在养成习惯这件事情上,我们可以从这个定律吸收到的经验就是,将坏习惯的步骤尽可能加多,将好习惯的步骤尽可能减少。打个比方,如果你想要戒烟,那么可以把家里的烟统统交给你老婆保管,然后每次藏在不同的地方,甚至可以设置动态密码,这样每次你想要吸烟的时候就需要层层步骤才能最终实现,成本越大,你的动力也就消耗的越快,逐步就失去了想要吸烟的那种冲动;如果你想要培养跑步的习惯,可以提前把跑步鞋、健身的衣服、水等东西提前准备好,放在家门口鞋柜边上,每次回到家放下包就可以直接换衣服出发跑步,那么坚持下来的概率就会大很多,否则你可能就会因为要找鞋子、找水、换衣服等步骤消耗掉了你为数不多的健身冲动。
- “猛火炖,慢火煮”:意思是说在培养习惯这方面,可能不太适合循序渐进,比如坚持早起这件事,坚持一周 8 点半早起,再提前到坚持一周 8 点早起,之后再提前到 7 点半早起,效果可能并不比直接 7 点半起床效果更好。猛火炖的意思就是下定决定要做这件事的话,要立马跟过去告别,做出改变, 比如第二天就开始 7 点半起床;慢火煮的意思就是不要退回原来的状态,想尽办法坚持下去,几天之后效果就会完全不同。如果真的因为早起白天十分没精神,坚持不要睡,晚上回家早点倒头大睡,第二天再 7 点半起床,连续几天之后你就会发现很轻松了。
更具体的内容可以参考一下《游戏改变世界》这本书。
如何让想法落地
这章主要是介绍如何将你的灵感和想法逐步落到实处,对我自己来说,收获最大的是其中提到的“六个高度”。
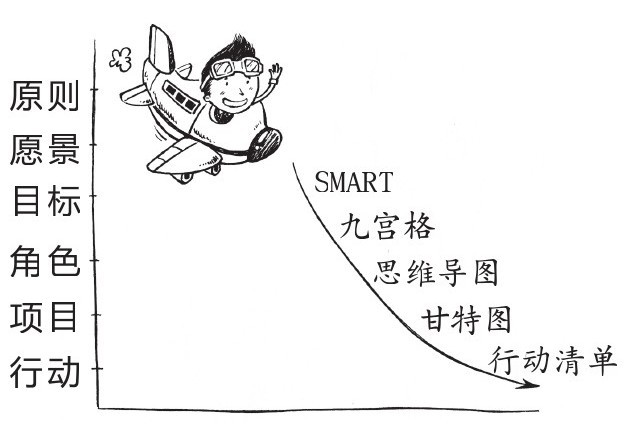
David Allen提出我们的工作和人生是可以划分成六个高度去进行检视和规划的。
具体如下:
- 原则:你首先必须要找个时间好好地思考一下自己的价值观、原则和目标,这是你工作的灵魂所在。书中老付的原则是:高效率,慢生活。感觉这个原则很棒,可以用来参考。只有提高效率,才能有更充分的时间去享受生活。
- 愿景:这里面包含3~5年的工作目标,可以是职位的,也可以是组织能力、协调能力等。这个阶段找到一个参照物是比较重要的,例如,你想要什么?哪些人已经做到了?他们是如何做到的?有了参照物会让你的目标更加清晰。
- 目标:目标是比愿景更细化的东西,通常在一年内就可以有一个阶段性的成果。类似于每年制定一个年度计划,需要有稍微明确一点的目标。
- 责任范围:工作上的角色,如销售、管理、产品开发等;生活中的角色,如家庭、个人财务、精神层面等。我们不只是有工作,更重要的是有家庭、有朋友、有日常生活等,这部分讲的是如何在这些角色之间做好平衡
- 任务:这包含了任务和项目。
- 行动:这是最为细枝末节的事件,我们要将它们全部放进行动清单,然后一一消灭。
这一部分也可以参考 《ORK 工作法》,使用 OKR 来制定你的个人目标。
同时这里针对每一个阶段,也有不同的工具可以用来帮助我们梳理目标。
在梳理个人目标的时候,SMART 原则十分有用,通常是公司里用来制定 KPI 的时候需要用到,他代表的意思是 Specific—目标明确、Measurable—目标可衡量、Attainable—目标可实现、Relevant—目标与其他目标具有相关性、Time-based—目标必须要有截止时间。
明确自己的角色以及平衡各种角色的时候,九宫格就派上用场了,你制定的目标中,不仅要包含自己的工作计划,还需要考虑过程中其他角色的精力分配,例如如何维持人际关系、如何保持身体健康、如何提升财富水平等等。

接下来的任务和项目维度,可以分别使用思维导图和甘特图来进行梳理。
思维导图是很适合用来理清楚事情脉的,相比起文字版的待办清单,人对图像的接受程度和记忆力明显更高,因为清单本身是一个列表形式,而导图可以直接看到全貌。同时,也有助于跟他人进行分享演示。这里导图中还有很多分支,例如鱼骨图、时间线等等,适用于更加特定的细分场景。
甘特图是项目管理的利器,通常来说,项目管理管理的就是资源,包括时间、人力等,而甘特图可以很好地进行人力分配,看到全局进度,明确每个人的任务情况。可以很方便的进行周报汇总、风险预警等。
个人实践
至此,这篇文章的主要核心点基本已经梳理完毕,不管是从篇幅上来说,还是重要程度上来说,我觉得核心主要在于第二章 GTD 相关部分。
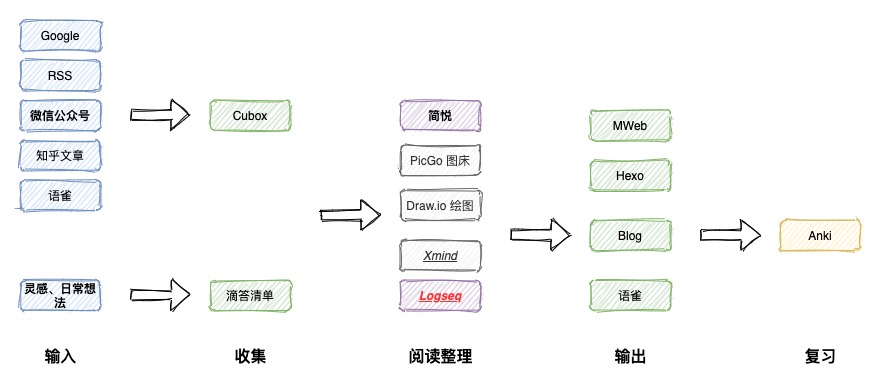
接下来,我简单分享一下我自己在时间管理方面所形成的小系统以及用到的一些工具。
时间块记录
这部分内容其实在上面已经提到了,我目前用下来比较方便的软件分别是
同时,记录任务完成情况的话,可以通过语雀做一个 Excel 模板,每天进行更新。不过这部分主要是用来明确你自己平时的工作效率是否高效,同时明确你自己的高效工作时间段,我个人觉得靠手工录入时间块或者记录完成情况的方式,几乎是不可持续的,毕竟人都是有惰性的,简单执行一两周达到目标即可。不过类似 Qbserve 这种,如果有类似安卓端的工具,可以直接跟电脑打通,自动记录全部的时间使用信息,还是蛮不错的。
灵感捕捉
基于上面提到的灵感捕捉原则,在挑选这方面软件的时候,就必须要满足以下条件:
- 跨平台支持优秀
- 手机端能够快速输入
- 最好可以识别自然语言
我选择的软件分别是 Cubox 以及 滴答清单,他们各自有着不同的使用场景。
针对公众号或者 RSS 获取到的信息,如果想要临时记录下来后续抽时间处理,可以使用 Cubox,它最大的优点就是能够直接在微信公众号的浏览过程中通过发送到助手直接进行保存,而不用拷贝链接切换软件保存或者使用捷径保存,打断次数越少越好。
而滴答清单,不得不说真的是个良心神器,我已经是三四年的老用户了,它的优势包括:
- 自然语言识别很强,例如输入明天去超市 xx,每个月写一次总结等都可以设置好对应的任务,十分方便
- 跨平台非常优秀,可以在手机端添加桌面小组件,几乎是秒级进入输入状态
- 支持智能清单,作用是可以自己使用一些条件进行汇总查询,例如哪些事情重要且紧急、重要不紧急等等,配合 GTD 食用感觉非常棒。
- 最重要的一点,绝大部分功能都是免费的,可以说是非常良心了。
更详细的关于 PKM 中信息获取以及整理可以参考之前的一篇文章: 万字长文—关于PKM收集与整理系统的思考和实践
组织整理
这里可以按照作者的方式,将待办事项分为项目清单、将来清单、行动清单。我个人在实际实践过程中,新补充了一些自行添加的清单:
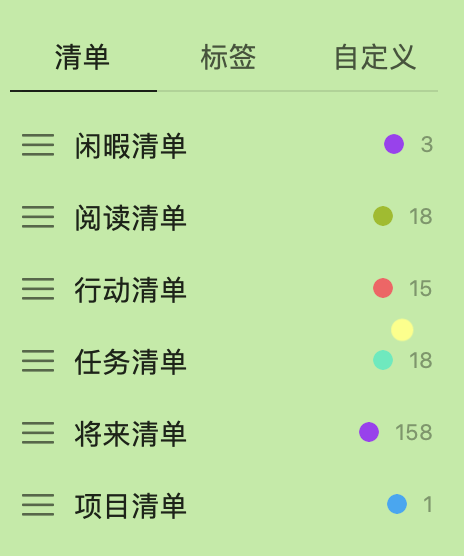
- 任务清单:在使用项目清单和行动清单的过程中,我发现如果把任务拆解为细分的行动清单固然可以做到无脑执行下一步行动即可,但是在实际操作过程中,容易丢失上下文,因为不同的任务可能会并行开展,这时候就有可能产生上下文混淆。我个人还是把任务单独作为一个清单拎出来,把一些比较独立,可以直接进行的行动放到行动清单中。
- 阅读清单:单独针对阅读梳理了一个清单,定期进行阅读,实际并没有:)
- 闲暇清单:这个也是在实践的过程中,发现一个人一天能够保持高效的工作时间通常不超过 4 个小时,那么剩下的时间很多都在划水,这时候可以穿插做一些不是那么消耗精力的事情,例如,整理收集箱、设置行动的截止时间、设置行动的优先级等等。
我的滴答清单使用完整流程大概是这样:
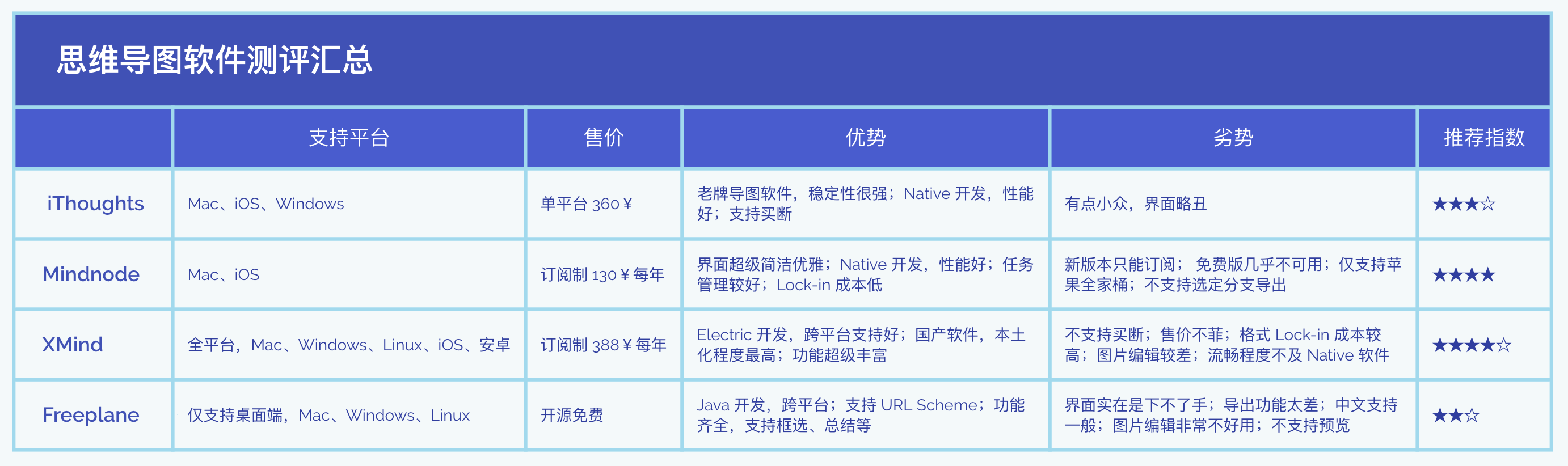
同时这里,配合项目清单和任务清单的拆解,还需要使用思维导图工具和甘特图工具,这里我选择使用的软件分别是 Xmind 和 Omniplan。XMind 是一款国产的跨平台思维导图软件,目前使用下来最符合我的需求,后面会单独写一篇测评;Omniplan就不说了,Omni 系列属于知名高效工作组件了,目前出的产品几乎各个精品,OmniFocus 也是一款非常棒的 GTD 软件,我之前也使用过一段时间,不过由于功能太强大也就是太复杂,最后还是转投滴答清单了。
深思
我目前深思的方式包括每日日记、每周计划及回顾、年度计划等,这里除了 Markdown 以外,强烈推荐 Textexpander 这款软件,这是一款快速输入文字的软件,内置了很多有用的函数,例如当前日期、时间戳,还可以进行不同 snippets 的组合,我几乎每天都在使用。
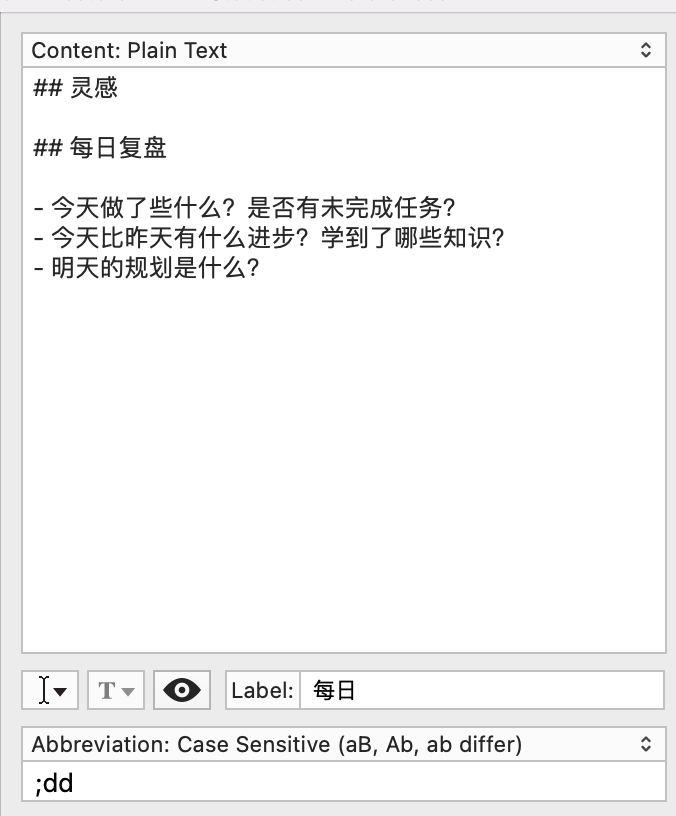
这样每次当你输入 ;dd 的时候,都会自动展开为今日日记,节约了大量的输入工作。类似的软件还有很多,例如Alfred 也支持快速输入文字,不过时间格式方面自由度太低,其他倒还不错。
行动
这里我建议还是入手一个降噪耳机,能够大幅度提升幸福感,避免外界嘈杂的声音干扰你。搭配白噪声软件效果更佳。
同时这里不得不再次提一下良心的滴答清单,不过支持番茄钟的功能,甚至还支持了白噪声。
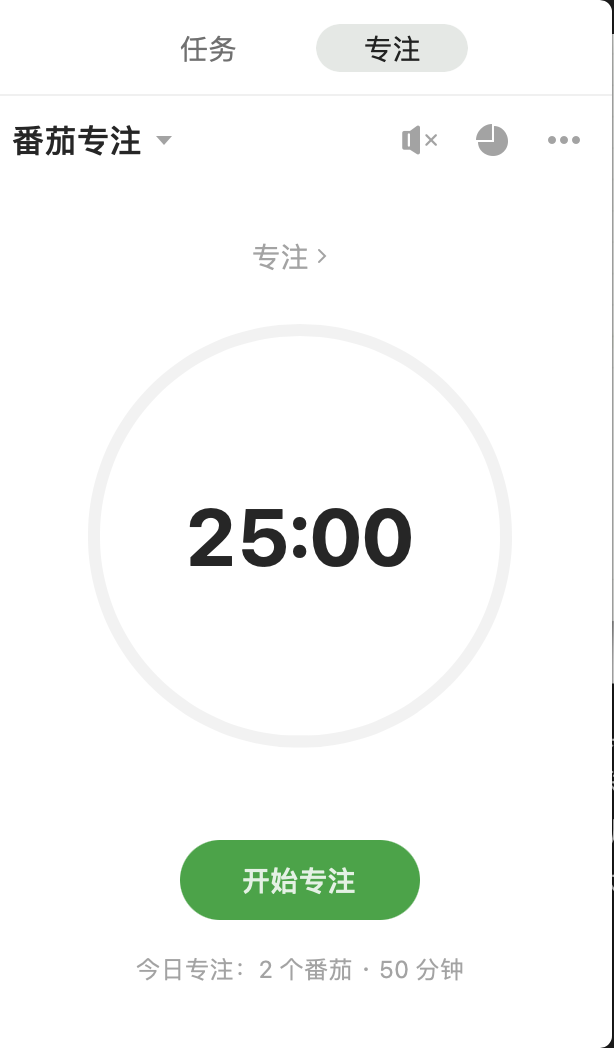
界面大概长这样,使用起来十分方便,而且还支持统计功能,可以自行设置每个番茄的时间,连续 4 个番茄之后的间隔休息时间等等,可以说是非常贴心了。
总结
至此,关于我个人在阅读这本书的心得和笔记,包括我的一些实际实践都已经介绍完了,如果大家也对时间管理感兴趣,欢迎来一起留言讨论~
]]>















 ,中间尝试了各种方案,一度怀疑是否只能使用坚果云才能用知识库功能。 结果发现全部卸载重装之后,坚果云也无法使用,中间联系简悦作者
,中间尝试了各种方案,一度怀疑是否只能使用坚果云才能用知识库功能。 结果发现全部卸载重装之后,坚果云也无法使用,中间联系简悦作者  ,因为我只用简悦来进行深度阅读,并不需要在这里查看标注,所以通常都是进入阅读模式。
,因为我只用简悦来进行深度阅读,并不需要在这里查看标注,所以通常都是进入阅读模式。









 ,测试的双拼是
,测试的双拼是  。
。 ,你应该能想象出来,这是有多么蛋疼。
,你应该能想象出来,这是有多么蛋疼。 ,但当你等了一小时之后,依然卡在这里的时候,你大概也会像我一样怀疑人生了。不确定这个 bug 是否跟中文有关。
,但当你等了一小时之后,依然卡在这里的时候,你大概也会像我一样怀疑人生了。不确定这个 bug 是否跟中文有关。